![[RSS]](./theme/image/rss.png)
GAVO at the Fall 2023 Interop in Tucson
The Virtual Observatory, in practical terms, is the set of standards created and maintained by the IVOA. The IVOA, in turn, is a community almost defined by the two conferences it holds every year, the Interops (previously on this blog). The most recent Interop has just ended: The 2023 Tucson Fall Interop. Here are a few notes on what went on there from my (and to some extent GAVO's) perspective.

This fall's IVOA Interop was hosted by Steward Observatory, where they had ripening oranges in the backyard. They were edible!
For at least a decade and a half, the autumn Interops have been back-to-back with the ADASS conferences. ADASS, short for Astronomical Data Analysis Software and Systems, is a venerable conference series, created far in the last century (this year: ADASS XXXIII) to have a forum for people who work in the magic triangle of astronomy, instrumentation, and data processing. Clearly, such a forum is very well suited to spread the word about the miracles we are working in the VO.
To that end, I was involved in the creation of three posters: One on the use of MOCs in TAP – a somewhat extended version of something you saw on this blog first –, then one on data discovery in pyVO by Renaud Savalle (Paris) et al – a topic again familiar to readers of this blog – and finally one on improving the description of ADQL to enable more reliable machine validation of its grammar by Grégory Mantelet (Strasbourg) et al.
As the conference at large goes, I was really delighted to see how basically everyone talking about data publication at all was stressing they are “doing VO”, which was a very welcome change from, perhaps, 10 years ago when this kind of talk was typcially extolling the virtues of one particular web or javascript framework. One of the great thing about standards in general and the VO in particular is that they tend to be a lot more durable than all those frameworks.
The following Interop was a “short” one, lasting from Friday morning until Sunday noon, which meant that I was far too busy to do anything like a live blog while it went on. Let me hence just briefly point out the main talks related to GAVO's current activities and DaCHS.
In Data Curation and Preservation on Saturday morning, Baptiste Cecconi (Paris) gave a nice overview of – among other things – what our bridge between the Registry and b2find (in particular, using the VOResource to DataCite mapper) enables in the context of the EOSC, and he briefly touched the question of how to properly make landing pages for VO resources (for which I am currently using another piece of XSLT).
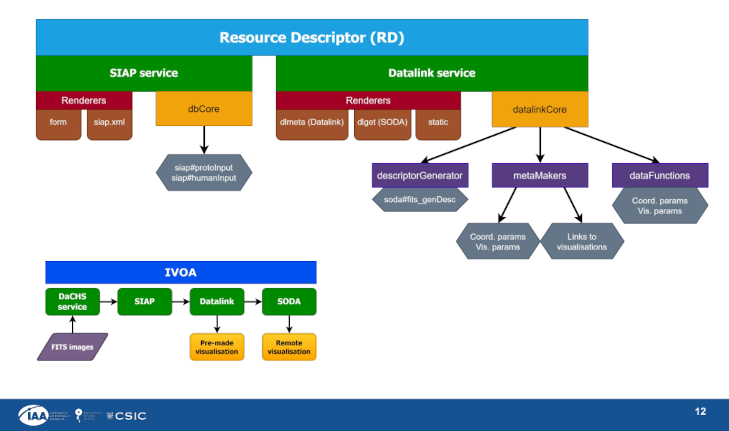
In the Radio session later that morning, Ixaka Labadie (Granada) gave a talk on how he is using DaCHS to deliver 3D visualisations for fairly impressive (prototype) SKA data. I particularly liked his illustrations of how DaCHS does Datalink and SODA. See his slide 12:
In the afternoon, there was the Registry session, which featured me talking about the harvest trigger service I have been running for a while to help people across the anticlimactic moment when you have published your new resource but it won't show up in TOPCAT or pyVO for a day or so.
The bulk of this session, however, was used for a discussion about various shortcomings of the Registry or its interfaces that I found pleasantly productive – incidentally, just like the discussion on word lists in EPN-TAP on Friday afternoon's Solar System Session that I had the pleasure to chair.
In the DAL session on that afternoon, I had two talks: One was on the proposed new interoperable user-defined functions already implemented in DaCHS' ADQL and now coming up in several other services, too. Note to self: Some of these would probably be rather suitable blog post material.
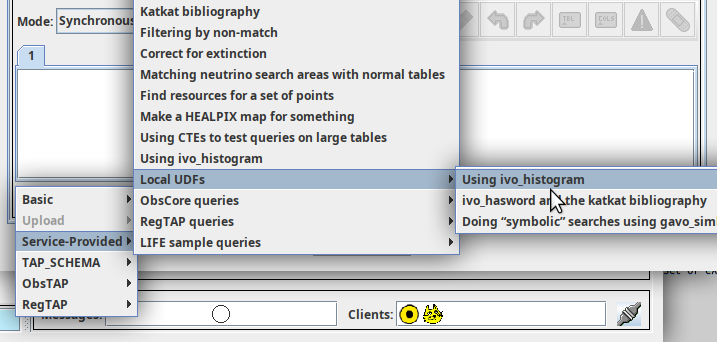
The second talk was a sort of brief show-and-tell pitch, in which I pointed out that hierarchical TAP examples using the elegant examples:continued property now actually work in both pyVO and TOPCAT:
Finally, in Sunday morning's Apps session, I talked about global image discovery in pyVO. This was about an early promise of the VO: just say where in space, time, and spectrum you need an image (or spectrum, or time series, or whatever), and some apparatus will find and query all the services that could have pertinent data. It would then present the metadata of the datasets it found in some useful form that would let you make informed decisions which to fetch.
This was not too difficult in the olden days, but by now the VO is so big and complicated that a pyVO module with fairly involved logic is required. If you don't want to read the notes here, don't worry: I can safely predict that you'll read more about that topic on this blog.
This is nowhere near done yet; so, it is one more piece of homework that I am taking home with me.